그래프란
노드(N : Node)와 그 노드를 연결하는 간선(E: Edge)을 하나로 모아 놓은 자료구조이다.
즉, 연결되어 있는 객체 간의 관계를 표현할 수 있는 자료구조이다.
ex) 지도, 지하철 노선도의 최단 경로, 전기 회로의 소자들
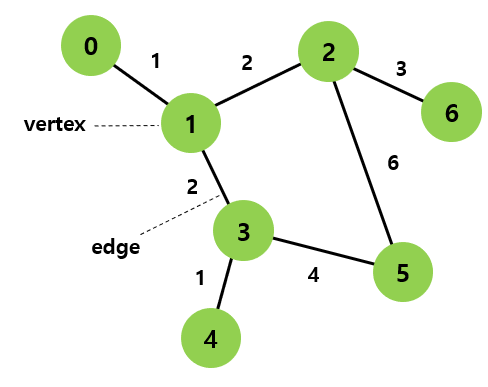
그래프(Graph)와 관련된 용어
정점(vertex): 위치라는 개념. (node 라고도 부름)
간선(edge): 위치 간의 관계. 즉, 노드를 연결하는 선 (link, branch 라고도 부름)
인접 정점(adjacent vertex): 간선에 의 해 직접 연결된 정점
정점의 차수(degree): 무방향 그래프에서 하나의 정점에 인접한 정점의 수
무방향 그래프에 존재하는 정점의 모든 차수의 합 = 그래프의 간선 수의 2배
진입 차수(in-degree): 방향 그래프에서 외부에서 오는 간선의 수 (내차수 라고도 부름)
진출 차수(out-degree): 방향 그래픙에서 외부로 향하는 간선의 수 (외차수 라고도 부름)
방향 그래프에 있는 정점의 진입 차수 또는 진출 차수의 합 = 방향 그래프의 간선의 수(내차수 + 외차수)
경로 길이(path length): 경로를 구성하는 데 사용된 간선의 수
단순 경로(simple path): 경로 중에서 반복되는 정점이 없는 경우
사이클(cycle): 단순 경로의 시작 정점과 종료 정점이 동일한 경우
n : 정점수
m : 간선수
v : 차수
루프와 병렬 간선이 없는 무방향 그래프에서 m ≤ n(n-1)/2
방향그래프에서는 m ≤ n(n-1)
무방향 그래프 VS 방향 그래프
- 무방향 그래프(Undirected Graph)
- 무방향 그래프의 간선은 간선을 통해서 양 방향으로 갈 수 있다.
- 정점 A와 정점 B를 연결하는 간선은 (A, B)와 같이 정점의 쌍으로 표현한다.
- (A, B)는 (B, A) 동일 Ex) 양방향 통행 도로
- 방향 그래프(Directed Graph)
- 간선에 방향성이 존재하는 그래프
- A -> B로만 갈 수 있는 간선은 <A, B>로 표시한다.
- <A, B>는 <B, A>는 다름
방향간선과 무방향간선
방향간선은 방향이 있는 간선
무방향간선은 방향이 없는 간선이다.
그래프와 트리
그래프(Graph)의 구현 2가지
1. 인접 리스트(Adjacency List)
인접 리스트(Adjacency List)로 그래프를 표현하는 것이 가장 일반적인 방법 이다.
- 모든 정점(혹은 노드)을 인접 리스트에 저장한다. 즉, 각각의 정점에 인접한 정점들을 리스트로 표시한 것이다.
- 배열(혹은 해시테이블)과 배열의 각 인덱스마다 존재하는 또 다른 리스트(배열, 동적 가변 크기 배열(ArrayList), 연결리스트(LinkedList) 등)를 이용해서 인접 리스트를 표현한다.
0: 1, 2, 3 1: 0, 2 2: 0, 1, 3 3: 0, 2- 정점의 번호만 알면 이 번호를 배열의 인덱스로 하여 각 정점의 리스트에 쉽게 접근할 수 있다.
- 무방향 그래프(Undirected Graph)에서 (a, b) 간선은 두 번 저장된다.
- 한 번은 a 정점에 인접한 간선을 저장하고 다른 한 번은 b에 인접한 간선을 저장한다.
- 정점의 수: N, 간선의 수: E인 무방향 그래프의 경우
- N개의 리스트, N개의 배열, 2E개의 노드가 필요
- 트리에선 특정 노드 하나(루트 노드)에서 다른 모든 노드로 접근이 가능 -> Tree 클래스 불필요
- 그래프에선 특정 노드에서 다른 모든 노드로 접근이 가능하지는 않음 -> Graph 클래스 필요
class Graph { public Node[] nodes; } // 트리의 노드 클래스와 동일 class Node { public String name; public Node[] children; }
2. 인접 행렬(Adjacency Matrix)
인접 행렬은 NxN 불린 행렬(Boolean Matrix)로써 matrix[i][j]가 true라면 i -> j로의 간선이 있다는 뜻이다.
0과 1을 이용한 정수 행렬(Integer Matrix)을 사용할 수도 있다.
if(간선 (i, j)가 그래프에 존재)
matrix[i][j] = 1;
else
matrix[i][j] = 0;
- 정점(노드)의 개수가 N인 그래프를 인접 행렬로 표현
- 간선의 수와 무관하게 항상 n^2개의 메모리 공간이 필요하다.
- 무방향 그래프를 인접 행렬로 표현한다면 이 행렬은 대칭 행렬(Symmetric Matrix)이 된다.
- 물론 방향 그래프는 대칭 행렬이 안 될 수도 있다.
- 인접 리스트를 사용한 그래프 알고리즘들(Ex. 너비 우선 탐색) 또한 인접 행렬에서도 사용이 가능하다.
- 하지만 인접 행렬은 조금 효율성이 떨어진다.
- 인접 리스트는 어떤 노드에 인접한 노드들을 쉽게 찾을 수 있지만 인접 행렬에서는 인접한 노드를 찾기 위해서는 모든 노드를 전부 순회해야 한다.
밀집도
희소 그래프 vs 밀집 그래프
정점의 개수와 비교해 상대적으로 간선이 적으면 희소그래프,
정점의 개수와 비교해 상대적으로 간선이 많으면 밀집그래프이다.
중요한 것은 밀집도에 따라 알고리즘이 달라질 수 있다.
인접 리스트와 인접 행렬 중 선택 방법
- 인접 리스트
- 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph) 의 경우
- 장점
- 어떤 노드에 인접한 노드들 을 쉽게 찾을 수 있다.
- 그래프에 존재하는 모든 간선의 수 는 O(N+E) 안에 알 수 있다. : 인접 리스트 전체를 조사한다.
- 단점
- 간선의 존재 여부와 정점의 차수: 정점 i의 리스트에 있는 노드의 수 즉, 정점 차수만큼의 시간이 필요
- 인접 행렬
- 그래프에 간선이 많이 존재하는 밀집 그래프(Dense Graph) 의 경우
- 장점
- 두 정점을 연결하는 간선의 존재 여부 (M[i][j])를 O(1) 안에 즉시 알 수 있다.
- 정점의 차수 는 O(N) 안에 알 수 있다. : 인접 배열의 i번 째 행 또는 열을 모두 더한다.
- 단점
- 어떤 노드에 인접한 노드들을 찾기 위해서는 모든 노드를 전부 순회해야 한다.
- 그래프에 존재하는 모든 간선의 수는 O(N^2) 안에 알 수 있다. : 인접 행렬 전체를 조사한다.
시간 복잡도
N = Node의 개수, E = Edge의 전체 개수로 표현
인접리스트
- Node 추가 : O(1)
- 이중연결리스트 꼬리 nextNode로 지정하기 때문에 상수 시간만큼 소요된다.
- Node 삭제 : O(N+E)
- 노드를 삭제하면 삭제된 공간을 채우기 위해 다시 색인하는 과정이 필요하므로 노드, 정점의 개수를 합한 만큼의 시간이 소요된다.
- Edge 추가 : O(1)
- Edge 삭제 : O(E)
- 최악의 상황은 한 줄로 노드가 연결되어 있는 경우이다. 삭제하기 위해 마지막 Edge까지 탐색해야 한다.
인접행렬
- Node 추가 : O(N^2)
- 행과 열을 모두 추가해야 하므로 노드 개수의 제곱 만큼의 시간이 필요하다. 추가로 새로 생긴 행과 열에 대한 각 셀을 채워야 한다.
- Node 삭제 : O(N^2)
- Edge 추가 : O(1)
- Edge 추가는 특정 셀의 값만 변경(0, 1)하면 되므로 상수 시간만큼 소요됩니다.
- Edge 삭제 : O(1)
- Edge 삭제는 특정 셀의 값만 변경(0, 1)하면 되므로 상수 시간만큼 소요됩니다.
상대적으로 인접리스트는 Node의 추가, 삭제가 빈번하게 발생하는 경우 사용하는 것이 좋습니다.
상대적으로 인접행렬은 Edge의 추가, 삭제가 빈번하게 발생하는 경우 사용하는 것이 좋습니다
그래프(Graph)의 탐색
일반적인 방법 두 가지:깊이 우선 탐색(Depth-First Search) 과 너비 우선 탐색(Breadth-First Search)
1. 깊이 우선 탐색(DFS, Depth-First Search)
루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법
- 즉, 넓게(wide) 탐색하기 전에 깊게(deep) 탐색하는 것이다.
- 사용하는 경우: 모든 노드를 방문 하고자 하는 경우에 이 방법을 선택한다.
- 깊이 우선 탐색이 너비 우선 탐색보다 좀 더 간단하다.
2. 너비 우선 탐색(BFS, Breadth-First Search)
루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법
- 즉, 깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 것이다.
- 사용하는 경우: 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다.
- Ex) 지구상에 존재하는 모든 친구 관계를 그래프로 표현한 후 Ash와 Vanessa 사이에 존재하는 경로를 찾는 경우
- 깊이 우선 탐색의 경우 - 모든 친구 관계를 다 살펴봐야 할지도 모른다.
- 너비 우선 탐색의 경우 - Ash와 가까운 관계부터 탐색
https://gmlwjd9405.github.io/2018/08/13/data-structure-graph.html
https://wjjeong.tistory.com/38
그래프
그래프란
노드(N : Node)와 그 노드를 연결하는 간선(E: Edge)을 하나로 모아 놓은 자료구조이다.
즉, 연결되어 있는 객체 간의 관계를 표현할 수 있는 자료구조이다.
ex) 지도, 지하철 노선도의 최단 경로, 전기 회로의 소자들
그래프(Graph)와 관련된 용어
정점(vertex): 위치라는 개념. (node 라고도 부름)
간선(edge): 위치 간의 관계. 즉, 노드를 연결하는 선 (link, branch 라고도 부름)
인접 정점(adjacent vertex): 간선에 의 해 직접 연결된 정점
정점의 차수(degree): 무방향 그래프에서 하나의 정점에 인접한 정점의 수
무방향 그래프에 존재하는 정점의 모든 차수의 합 = 그래프의 간선 수의 2배
진입 차수(in-degree): 방향 그래프에서 외부에서 오는 간선의 수 (내차수 라고도 부름)
진출 차수(out-degree): 방향 그래픙에서 외부로 향하는 간선의 수 (외차수 라고도 부름)
방향 그래프에 있는 정점의 진입 차수 또는 진출 차수의 합 = 방향 그래프의 간선의 수(내차수 + 외차수)
경로 길이(path length): 경로를 구성하는 데 사용된 간선의 수
단순 경로(simple path): 경로 중에서 반복되는 정점이 없는 경우
사이클(cycle): 단순 경로의 시작 정점과 종료 정점이 동일한 경우
n : 정점수
m : 간선수
v : 차수
루프와 병렬 간선이 없는 무방향 그래프에서 m ≤ n(n-1)/2
방향그래프에서는 m ≤ n(n-1)
무방향 그래프 VS 방향 그래프
- 무방향 그래프(Undirected Graph)
- 무방향 그래프의 간선은 간선을 통해서 양 방향으로 갈 수 있다.
- 정점 A와 정점 B를 연결하는 간선은 (A, B)와 같이 정점의 쌍으로 표현한다.
- (A, B)는 (B, A) 동일 Ex) 양방향 통행 도로
- 방향 그래프(Directed Graph)
- 간선에 방향성이 존재하는 그래프
- A -> B로만 갈 수 있는 간선은 <A, B>로 표시한다.
- <A, B>는 <B, A>는 다름
방향간선과 무방향간선
방향간선은 방향이 있는 간선
무방향간선은 방향이 없는 간선이다.
그래프와 트리
그래프(Graph)의 구현 2가지
1. 인접 리스트(Adjacency List)
인접 리스트(Adjacency List)로 그래프를 표현하는 것이 가장 일반적인 방법 이다.
- 모든 정점(혹은 노드)을 인접 리스트에 저장한다. 즉, 각각의 정점에 인접한 정점들을 리스트로 표시한 것이다.
- 배열(혹은 해시테이블)과 배열의 각 인덱스마다 존재하는 또 다른 리스트(배열, 동적 가변 크기 배열(ArrayList), 연결리스트(LinkedList) 등)를 이용해서 인접 리스트를 표현한다.
0: 1, 2, 3 1: 0, 2 2: 0, 1, 3 3: 0, 2- 정점의 번호만 알면 이 번호를 배열의 인덱스로 하여 각 정점의 리스트에 쉽게 접근할 수 있다.
- 무방향 그래프(Undirected Graph)에서 (a, b) 간선은 두 번 저장된다.
- 한 번은 a 정점에 인접한 간선을 저장하고 다른 한 번은 b에 인접한 간선을 저장한다.
- 정점의 수: N, 간선의 수: E인 무방향 그래프의 경우
- N개의 리스트, N개의 배열, 2E개의 노드가 필요
- 트리에선 특정 노드 하나(루트 노드)에서 다른 모든 노드로 접근이 가능 -> Tree 클래스 불필요
- 그래프에선 특정 노드에서 다른 모든 노드로 접근이 가능하지는 않음 -> Graph 클래스 필요
class Graph { public Node[] nodes; } // 트리의 노드 클래스와 동일 class Node { public String name; public Node[] children; }
2. 인접 행렬(Adjacency Matrix)
인접 행렬은 NxN 불린 행렬(Boolean Matrix)로써 matrix[i][j]가 true라면 i -> j로의 간선이 있다는 뜻이다.
0과 1을 이용한 정수 행렬(Integer Matrix)을 사용할 수도 있다.
if(간선 (i, j)가 그래프에 존재)
matrix[i][j] = 1;
else
matrix[i][j] = 0;
- 정점(노드)의 개수가 N인 그래프를 인접 행렬로 표현
- 간선의 수와 무관하게 항상 n^2개의 메모리 공간이 필요하다.
- 무방향 그래프를 인접 행렬로 표현한다면 이 행렬은 대칭 행렬(Symmetric Matrix)이 된다.
- 물론 방향 그래프는 대칭 행렬이 안 될 수도 있다.
- 인접 리스트를 사용한 그래프 알고리즘들(Ex. 너비 우선 탐색) 또한 인접 행렬에서도 사용이 가능하다.
- 하지만 인접 행렬은 조금 효율성이 떨어진다.
- 인접 리스트는 어떤 노드에 인접한 노드들을 쉽게 찾을 수 있지만 인접 행렬에서는 인접한 노드를 찾기 위해서는 모든 노드를 전부 순회해야 한다.
밀집도
희소 그래프 vs 밀집 그래프
정점의 개수와 비교해 상대적으로 간선이 적으면 희소그래프,
정점의 개수와 비교해 상대적으로 간선이 많으면 밀집그래프이다.
중요한 것은 밀집도에 따라 알고리즘이 달라질 수 있다.
인접 리스트와 인접 행렬 중 선택 방법
- 인접 리스트
- 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프(Sparse Graph) 의 경우
- 장점
- 어떤 노드에 인접한 노드들 을 쉽게 찾을 수 있다.
- 그래프에 존재하는 모든 간선의 수 는 O(N+E) 안에 알 수 있다. : 인접 리스트 전체를 조사한다.
- 단점
- 간선의 존재 여부와 정점의 차수: 정점 i의 리스트에 있는 노드의 수 즉, 정점 차수만큼의 시간이 필요
- 인접 행렬
- 그래프에 간선이 많이 존재하는 밀집 그래프(Dense Graph) 의 경우
- 장점
- 두 정점을 연결하는 간선의 존재 여부 (M[i][j])를 O(1) 안에 즉시 알 수 있다.
- 정점의 차수 는 O(N) 안에 알 수 있다. : 인접 배열의 i번 째 행 또는 열을 모두 더한다.
- 단점
- 어떤 노드에 인접한 노드들을 찾기 위해서는 모든 노드를 전부 순회해야 한다.
- 그래프에 존재하는 모든 간선의 수는 O(N^2) 안에 알 수 있다. : 인접 행렬 전체를 조사한다.
시간 복잡도
N = Node의 개수, E = Edge의 전체 개수로 표현
인접리스트
- Node 추가 : O(1)
- 이중연결리스트 꼬리 nextNode로 지정하기 때문에 상수 시간만큼 소요된다.
- Node 삭제 : O(N+E)
- 노드를 삭제하면 삭제된 공간을 채우기 위해 다시 색인하는 과정이 필요하므로 노드, 정점의 개수를 합한 만큼의 시간이 소요된다.
- Edge 추가 : O(1)
- Edge 삭제 : O(E)
- 최악의 상황은 한 줄로 노드가 연결되어 있는 경우이다. 삭제하기 위해 마지막 Edge까지 탐색해야 한다.
인접행렬
- Node 추가 : O(N^2)
- 행과 열을 모두 추가해야 하므로 노드 개수의 제곱 만큼의 시간이 필요하다. 추가로 새로 생긴 행과 열에 대한 각 셀을 채워야 한다.
- Node 삭제 : O(N^2)
- Edge 추가 : O(1)
- Edge 추가는 특정 셀의 값만 변경(0, 1)하면 되므로 상수 시간만큼 소요됩니다.
- Edge 삭제 : O(1)
- Edge 삭제는 특정 셀의 값만 변경(0, 1)하면 되므로 상수 시간만큼 소요됩니다.
상대적으로 인접리스트는 Node의 추가, 삭제가 빈번하게 발생하는 경우 사용하는 것이 좋습니다.
상대적으로 인접행렬은 Edge의 추가, 삭제가 빈번하게 발생하는 경우 사용하는 것이 좋습니다
그래프(Graph)의 탐색
일반적인 방법 두 가지:깊이 우선 탐색(Depth-First Search) 과 너비 우선 탐색(Breadth-First Search)
1. 깊이 우선 탐색(DFS, Depth-First Search)
루트 노드(혹은 다른 임의의 노드)에서 시작해서 다음 분기(branch)로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방법
- 즉, 넓게(wide) 탐색하기 전에 깊게(deep) 탐색하는 것이다.
- 사용하는 경우: 모든 노드를 방문 하고자 하는 경우에 이 방법을 선택한다.
- 깊이 우선 탐색이 너비 우선 탐색보다 좀 더 간단하다.
2. 너비 우선 탐색(BFS, Breadth-First Search)
루트 노드(혹은 다른 임의의 노드)에서 시작해서 인접한 노드를 먼저 탐색하는 방법
- 즉, 깊게(deep) 탐색하기 전에 넓게(wide) 탐색하는 것이다.
- 사용하는 경우: 두 노드 사이의 최단 경로 혹은 임의의 경로를 찾고 싶을 때 이 방법을 선택한다.
- Ex) 지구상에 존재하는 모든 친구 관계를 그래프로 표현한 후 Ash와 Vanessa 사이에 존재하는 경로를 찾는 경우
- 깊이 우선 탐색의 경우 - 모든 친구 관계를 다 살펴봐야 할지도 모른다.
- 너비 우선 탐색의 경우 - Ash와 가까운 관계부터 탐색
https://gmlwjd9405.github.io/2018/08/13/data-structure-graph.html
'개발일지 > 자료구조+알고리즘' 카테고리의 다른 글
| 다익스트라 알고리즘 (0) | 2022.07.08 |
|---|---|
| 힙(heap) 자료구조 (0) | 2022.03.16 |
| 해시(Hash) (0) | 2022.02.08 |


